J’ai présenté dans mon article précédent les résultats de l’analyse du mot croisillon #TelAvivSurSeine, l’évènement au centre d’une polémique qui n’aurait jamais dû sortir des réseaux sociaux ni des cercles militants.
Ces résultats sont le fruit d’une analyse rationnelle et distanciée des tweets associés à ce hashtag, analyse à la portée d’un informaticien suffisamment à l’aise sous UNIX et familier du langage de programmation Python.
Je présenterai dans cet article les outils et techniques m’ayant permis d’effectuer cette analyse.
Le code est disponible dans mon repository GitHub.
Nous verrons comment extraire, explorer, synthétiser et visualiser de la connaissance à partir d’une importante masse d’information disponible sur Twitter. Ainsi nous verrons, entre autres, comment :
- visualiser l’évolution du nombre de tweets et retweets par heure
- identifier les comptes les plus retweetés ou mentionnés
- identifier les comptes ayant le plus tweeté ou retweeté
- comptabiliser les hashtags les plus utilisés
- identifier les photos les plus diffusées
- visualiser le réseau social constitué des 15 comptes ayant le plus (re)tweeté et des 15 comptes les plus retweetés :

Collecte des données
Vous devez évidemment disposer d’un compte Twitter. Si c’est le cas, connectez-vous sur le gestionnaire d’applications Twitter puis :
- remplissez le formulaire de création d’une application Twitter.
- cliquer sur l’onglet Keys and Access Token et générer le jeton d’accès (bouton Create my access token)
- récupérez :
- la clé de l’API (
Consumer Key) et son mot de passe (Consumer Secret) - le jeton d’accès (
Access Token) et son mot de passe (Access Token Secret)
- la clé de l’API (
Note : votre profil Twitter doit être renseigné avec un numéro de téléphone valide sans quoi il ne vous sera pas possible de créer une application.
L’utilisation de l’API Twitter est plafonnée selon des critères variables.
Vous ne pourrez par exemple pas faire plus de 15 appels à la requête GET followers/ids par quart d’heure. Néanmoins, un seul appel restitue jusqu’à 5000 identifiants de followers.
Fort heureusement, la librairie tweepy propose un mode (wait_on_rate_limit) permettant au client de temporiser lorsque le quota est atteint, puis de reprendre le processus.
Par ailleurs, notez que l’API de recherche (GET search/tweets) a une profondeur de 10 jours maximum.
Je mets à disposition un script Python implémentant la collecte des tweets, à adapter selon votre contexte et après avoir renseigné les vecteurs d’accréditation (Consumer key, Consumer secret, Access token, Access token secret).
Le mode opératoire d’installation est le suivant :
pip install tweepy
git clone https://github.com/ksahnine/datascience-twitter.gitEditez le script collect.py situé dans le répertoire datascience-twitter/scripts/collect et renseignez les variables consumer_key, consumer_secret, access_token et access_token_secret avec les vecteurs d’accéditation créés plus haut.
Ensuite, vous pourrez lancer la commande suivante afin de collecter les tweets en relation avec le hashtag #TelAvivSurSeine et dumper les résultats dans le répertoire ./data :
cd datascience-twitter/scripts/collect
python ./collect.py -s "#TelAvivSurSeine" -o "./data"Quelques préliminaires
Structure d’un tweet
Avant d’explorer les données, il est important de connaître la structure d’un tweet restitué par l’API Twitter. Elle est pleinement décrite sur le portail de dev de Twitter.
Pour vous donner une idée, voici un lien contenant un exemple complet de tweet au format JSON.
On trouvera ci-dessous une représentation très élaguée d’un tweet, ne contenant que les propriétés que nous exploiterons dans le cadre de cet article :
Voici une description des principaux champs :
.text: contenu du texte associé au tweet.created_at: date et heure UTC de création du tweet (ou retweet).source: support utilisé (terminal Android dans l’exemple).entities.hashtags: liste des mots croisillons contenu dans le tweet.entities.user_mentions: liste des comptes mentionnés dans le tweet.media: liste des ressources médias contenues dans le tweet (des images par exemple).user.screen_name: nom du compte ayant tweeté (ce qui suit après le caractère@).user.followers_count: nombre d’abonnés à ce compte.user.friends_count: nombre de comptes suivis.retweeted_status: contenu du tweet à l’origine du retweet.quoted_status: contenu du tweet à l’origine de la citation
Outils
J’ai une affinité particulière pour les outils en ligne de commande. Je vous recommande les suivants :
jqest un extraordinaire outil permettant de requêter des structures de données au format JSON. C’est un authentique couteau suisse absolument indispensable pour quiconque exploite des données sous ce format (c’est à dire, tout le monde…).
Bien qu’installable viapip, je vous conseille d’installer directement la version binaire pour votre plateforme 64 bits. A ce jour, la version 1.5 est disponible sous Linux, OS X, Windows ou d’autres plateformes
Je trouve que cet outil permet de mieux sentir les données. Par ailleurs, il peut être très efficacement associés à d’autres commandes Unix (wc,sort,sed,awk,joinetc.) jusqu’à obtenir le résultat final.gnuplotest un logiciel multiplateforme produisant des représentations graphiques de données en 2D ou 3Dcsvlookest un utilitaire permettant de formater proprement les données sous la forme de tableaux. Il est intégré au module Python csvkit dont le mode opératoire d’installation est des plus simples :pip install csvkit
Note : vérifier les prérequis d’installation en particulier sous Ubuntu
Exploration des données
Note : si vous souhaitez faire l’économie de la collecte des données et vous adonner directement à leur exploration, je mets à disposition un échantillon de données brutes (toute la journée du 10 Août 2015).
Pour récupérer le jeu de données :
git clone https://github.com/ksahnine/datascience-twitter.git
cd datascience-twitter
gunzip data/*.gzVisualisation
Produisons le fichier courbe_tweets.csv (séparateur ,) contenant la série temporelle du nombre de tweets par tranche horaire :
$ LANG=en_US
$ jq ".created_at" data/*.json | xargs -I ? date -j -f "%a %h %d %H:%M:%S %z %Y" "?" "+%Y-%m-%d_%H:00:00" | sort | uniq -c | sed -e 's/^ *//;s/ /,/' | awk -F"," '{ print $2 "," $1}' > courbe_tweets.csvNote : notez que l’heure UTC de création des tweets est convertie en heure locale
Une fois le fichier généré, produisons sa représentation graphique avec gnuplot :
$ gnuplot <<EOF
set datafile separator ","
set timefmt '%Y-%m-%d_%H:%M:%S'
set xdata time
set xtic rotate by -45 scale 0
set format x '%Y-%m-%d'
set ylabel "Nb tweets"
set grid ytics
set grid xtics
plot 'courbe_tweets.csv' u 1:2 with lines title 'Timeseries #TelAvivSurSeine'
EOF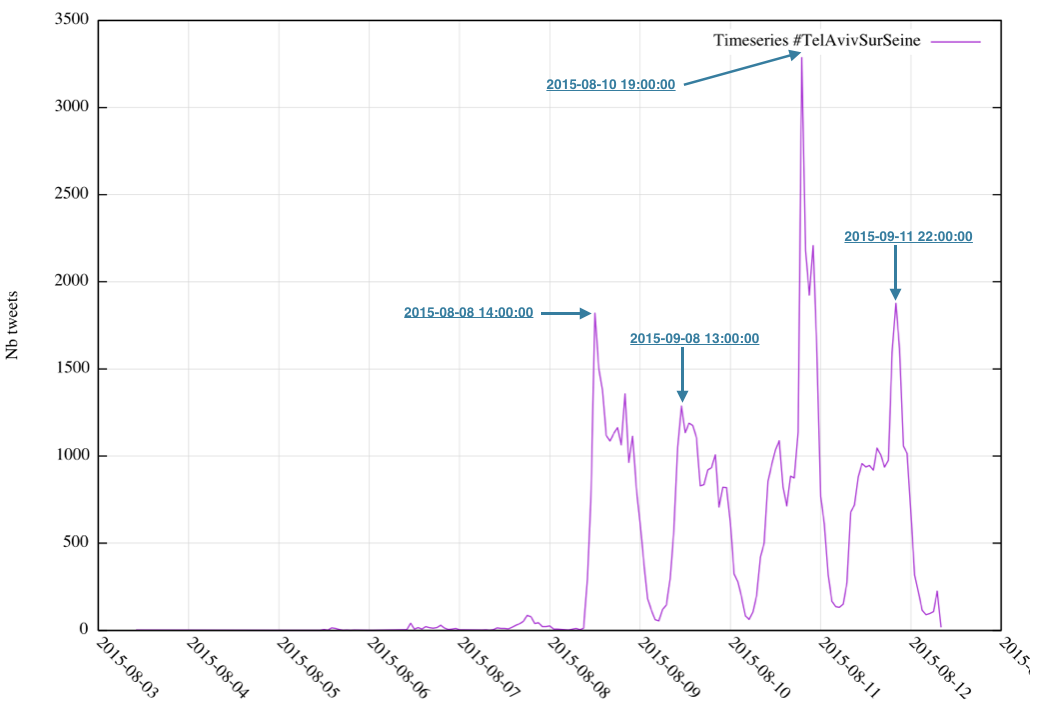
Autre exemple. Produisons le fichier devices.csv contenant la distribution des tweets par device :
$ jq ".source" data/*.json | sed 's/"\(<.*>\)\(.*\)\(<.*>\)"/\2/' | sort | uniq -c | sort -rn | sed -e 's/^ *//;s/ /,/' |head -8 > devices.csv La représentation graphique de la distribution sous la forme d’histogrammes est obtenue comme suit :
$ gnuplot <<EOF
set datafile separator ","
set style data histogram
set title "Distribution des tweets par device"
set xlabel "Devices"
set ylabel "Nb tweets"
set xtic rotate by -45 scale 0
set grid ytics
set style fill solid
plot 'devices.csv' u 1:xtic(2) notitle
EOF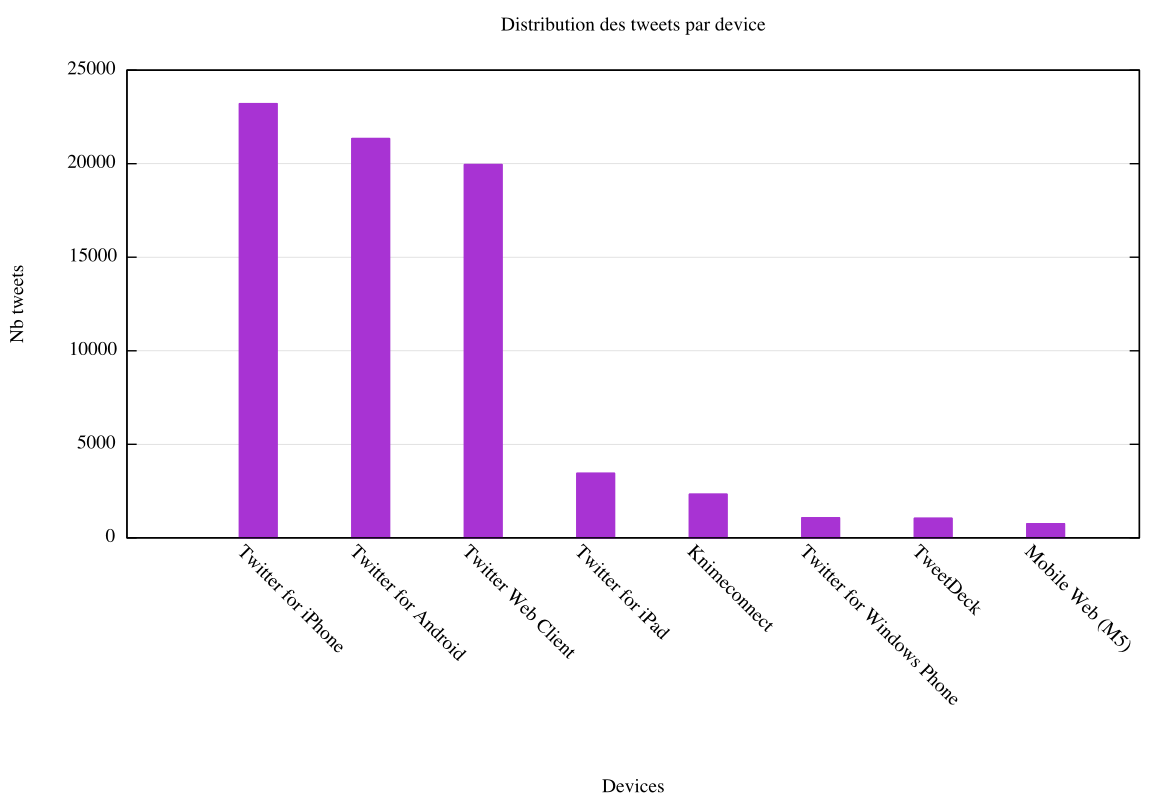
Eléments statistiques
Les commandes ci-dessous permettent d’obtenir différents indicateurs statistiques sur l’ensemble du jeu de données.
On verra dans le paragraphe suivant comment obtenir ces mêmes indicateurs sur une plage de temps restreinte :
- comptabiliser le nombre total de tweets :
$ wc -l data/*.json
76698 total- comptabiliser le nombre total de twittos (utilisateurs de Twitter) :
$ jq '.user.screen_name' data/*.json | sort -u | wc -l
16666- extraire les 5 photos les plus diffusées, avec leur nombre d’occurrences :
$ jq 'select(.entities.media!=null)|select(.entities.media[].type="photo")|.entities.media[].media_url' data/*.json | sort | uniq -c | sort -rn | head -5
478 "http://pbs.twimg.com/media/CL9DfpFWgAAZWQi.jpg"
434 "http://pbs.twimg.com/media/CL3vnXOWgAA67oa.jpg"
336 "http://pbs.twimg.com/media/CMC7JJxWsAAFDVD.jpg"
294 "http://pbs.twimg.com/media/CMEr3oWWwAAYbEf.png"
269 "http://pbs.twimg.com/media/CMEChkgWEAAIep-.jpg"- extraire les 4 types de clients Twitter les plus utilisés :
$ jq ".source" data/*.json | sed 's/"\(<.*>\)\(.*\)\(<.*>\)"/\2/' | sort | uniq -c | sort -rn | head -4
23210 Twitter for iPhone
21341 Twitter for Android
19954 Twitter Web Client
3444 Twitter for iPad- extraire les 3 comptes les plus retweetés (c’est un indicateur d’influence) avec le nombre de RT :
$ jq 'select(.retweeted_status!=null)|.retweeted_status.user.screen_name' data/*.json | sort | uniq -c | sort -rn | head -3
1759 "ybenderbal"
1085 "KarimaB_"
1054 "Linformatrice"- extraire les 3 comptes les plus cités (équivalent au retweet mais moins usité) avec le nombre de citations :
$ jq 'select(.quoted_status!=null)|.quoted_status.user.screen_name' data/*.json | sort | uniq -c | sort -rn | head -3
97 "Col_Connaughton"
52 "notstat"
49 "Farah_Gazan"- extraire les 3 comptes les plus mentionnés (c’est un indicateur de notoriété) avec le nombre de mentions :
$ jq ".entities.user_mentions[].screen_name" data/*.json | sort | uniq -c | sort -rn | head -3
8859 "Anne_Hidalgo"
1772 "ybenderbal"
1500 "BrunoJulliard"- dégager les 20 sentiments dominants en comptabilisant le nombre de hashtags :
$ jq ".entities.hashtags[].text" data/*.json | tr '[A-Z]' '[a-z]' | tr '[àâäéèêëîïôöùûü]' '[aaaeeeeiioouuu]' | sort | uniq -c | sort -rn | head -20
77070 "telavivsurseine"
5834 "apartheidsurseine"
2880 "israel"
2767 "gaza"
2406 "paris"
1868 "againsttelavivsurseine"
1860 "parisplages"
1668 "contretelavivsurseine"
1666 "telaviv"
1608 "gazasurseine"
1606 "parislovestlv"
1351 "palestine"
843 "freepalestine"
822 "bds"
787 "parisplage"
621 "france"
515 "icc4israel"
462 "hidalgo"
434 "apartheid"
372 "boycottisrael"Filtrer par date
Utilisons le sélecteur select/match supporté par jq pour filtrer sur la date de création du tweet created_at.
Ainsi, la commande suivante permet d’identifier les 3 comptes les plus retweetés le 10 Août entre 18h et 19h59 (soit entre 16h et 18h50 heure UTC) :
$ jq 'select(.created_at|match("Mon Aug 10 1[6-7].*"))|select(.retweeted_status!=null)|.retweeted_status.user.screen_name' data/*.json | sort | uniq -c | sort -rn | head -3
337 "Campagnebds"
114 "LePG"
100 "Thalwen"Formatage des résultats avec csvlook
Voyons comment afficher les 5 comptes les plus influents (i.e les plus retweetés) sous la forme d’un tableau à 3 colonnes : le nombre de RT, le nom du compte (.user.screen_name) et la date de création du compte (.user.created_at).
On utilisera un shell imbriqué à 2 commandes :
$ (echo "Nb RT,Compte,Date Creation"; jq --raw-output 'select(.retweeted_status!=null)|[.retweeted_status.user.screen_name,.retweeted_status.user.created_at] | @csv' data/*.json | sort | uniq -c | -k1rn | sed -e 's/^ *//;s/ /,/' | head -5 ) | csvlook
|--------+---------------+---------------------------------|
| Nb RT | Compte | Date Creation |
|--------+---------------+---------------------------------|
| 1759 | ybenderbal | Sun Mar 11 22:51:26 +0000 2012 |
| 1085 | KarimaB_ | Sat Mar 07 14:36:25 +0000 2009 |
| 1054 | Linformatrice | Thu Aug 04 02:18:52 +0000 2011 |
| 1045 | Campagnebds | Tue Dec 15 20:33:31 +0000 2009 |
| 916 | jeremo12 | Sun Feb 26 22:54:54 +0000 2012 |
|--------+---------------+---------------------------------|Magique ? Pas tant que ça. Décomposons la commande :
echo "Nb RT,Compte,Date Creation": affiche l’entête du tableaujq --raw-output 'select(.retweeted_status!=null)|[.retweeted_status.user.screen_name,.retweeted_status.user.created_at] | @csv' data/*.json:- filtre les éléments en ne retenant que ceux ayant une propriété
retweeted_statusnon nulle - puis affiche les valeurs
screen_nameetcreated_at - puis formate la sortie standard en CSV
- filtre les éléments en ne retenant que ceux ayant une propriété
sort | uniq -c: tri et comptage du nombre d’occurrences (nombre de RT)sort -k1rn: le flag-k1signifie que le tri s’effectue sur la première colonne (le nombre de RT)
Plus de statistiques
Je mets à disposition un script shell implémentant plusieurs routines suffisamment génériques pour s’adonner à tous types d’explorations de données.
cd datascience-twitter/scripts/analyseLa liste des routines implémentées s’obtient en exécutant la commande : ./compute.sh.
Pour obtenir la liste des 5 comptes les plus mentionnés sur toute la période :
./compute.sh tab_mentions "../../data/*.json" ".*" 5Pour obtenir la liste des 3 comptes les plus retweetés le 10 Août entre 18h et 19h59 heure de Paris :
./compute.sh tab_retweeted_users "../../data/*.json" "Aug 10 1[6-7]" 3Visualiser un réseau social
Je mets à disposition un script Python reconstituant le réseau de relations entre plusieurs utilisateurs Twitter.
Si vous avez bien suivi, vous ne devriez avoir aucun mal à produire un fichier contenant les 15 comptes les plus retweetés et les 15 comptes ayant le plus tweeté.
Sinon, vous pouvez utiliser mes routines :
./compute.sh csv_tweeted_users "../../data/*.json" ".*" 15 > users.csv
./compute.sh csv_retweeted_users "../../data/*.json " ".*" 15 >> users.csvReconstituons le réseau de relations entre ces utilisateurs :
./social-network.py -l users.csvPuis générons le réseau de relations :
./social-network.py -u users.csv > ../graph/data.csvPour visualiser le réseau de relation, lancer la commande suivante :
cd datascience-twitter/scripts/graph
./serve.shPour visualiser le résultat, ouvrir un navigateur et consulter le lien http://localhost:8000 :
open http://localhost:8000Le graphe orienté est généré à l’aide de l’excellente librairie D3 pour laquelle j’ai consacré un article il y a 3 ans.
Les cercles représentent les comptes. Leur taille est proportionnelle à leur nombre d’abonnés.
Il s’agit d’une version très expérimentale bien sûr, mais je trouve remarquable la formation de 2 groupes distincts de tweetos dont l’un concentre les tweets défavorables à l’évènement.
Par ailleurs, on visualise bien les signes révélateurs d’astroturfing.