Baptiste Coulmont, un universitaire spécialiste de la sociologie des prénoms, diffuse chaque année le classement des prénoms de candidats ayant obtenu une mention Très Bien au baccalauréat. Comme pour les années précédentes, ses résultats mettent en évidence une forme de déterminisme social où Apolline, par exemple, est beaucoup plus susceptible d’obtenir une mention que Jordan.
La médiatisation de ces travaux a suscité ma curiosité. En bon Unixien, je me suis adonné à la pratique de la science des données (data science) en ligne de commande, en prenant pour objet d’étude les résultats du brevet des collèges 2015 (série générale).
Sur le plan de l’analyse sociologique, j’aboutis aux mêmes conclusions que Baptiste Coulmont :
- Adèle, Apolline, Alix, Louise (entre autres) sont sur-représentées chez les détenteurs (détentrices devrais-je écrire) de la mention Très Bien au brevet des collèges alors que Steven, Alan, Dylan, Jordan ou Bryan sont les moins bien représentés
- par ailleurs, les filles obtiennent de bien meilleurs résultats scolaires que les garçons
La représentation visuelle du nuage des prénoms est réalisée avec GNU Plot, avec le pourcentage des mentions TB en abscisse et le nombre d’élèves en ordonnée (cliquer sur l’image pour l’agrandir).

Dans cet article, je décrirai chacune des étapes m’ayant permis d’établir ce résultat, en usant abondamment de la ligne de commande.
A travers cet article, j’espère pouvoir faire la démonstration qu’un Unixien est aussi un Data Scientist qui s’ignore.
L’ensemble du code dont il est fait référence dans l’article est disponible dans mon dépôt GitHub.
Plan de l’article :
Méthodologie et outils
Le site FranceTV info publie les résultats du brevet des collèges par commune, mais il ne s’agit que d’une publication partielle. Néanmoins, le site permet de constituer un échantillon significatif de plus de 250 000 résultats.
La méthode utilisée suit les étapes suivantes :
- Extraction des données : comme on peut s’en douter, aucun fichier formaté n’est mis à disposition. J’ai donc utilisé la technique du harvesting (ou web scraping) consistant à extraire le contenu du site, suivi d’un formatage afin de faciliter son exploitation ultérieure.
Techniquement, c’est un script développé en Python qui est chargé de l’extraction. Il s’appuie sur l’excellente librairie BeautifulSoup dont j’ai déjà vanté les qualités dans un précédent article.
Le script d’extraction est conçu pour être parallélisable, sans quoi la durée du traitement serait au bas mot d’une journée sur une machine de série. Il n’extrait que les résultats des collèges d’une commune dont l’identifiant est passé en paramètre. - Parallélisation des traitements : les traitements d’extraction et d’analyse des données sont distribués via GNU Parallel sur un cluster Amazon EC2 constitué de 10 instances
t2.micro(1 CPU 3,3 Ghz / 1 Go RAM) sous Ubuntu. La parallélisation est orchestrée depuis un portable sous OS X. Le schéma ci-dessous décrit l’architecture de l’ensemble :
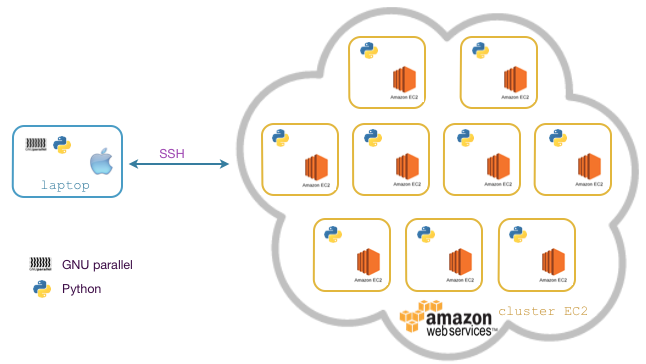
- Agrégation des données : la consolidation des données issue des traitements réalisés par le cluster est effectuée sur un portable (sous OS X) à l’aide des outils de tout bon Unixien (
grep,awk,sed,join,paste,bc,sort,uniq, etc) - Visualisation : pour faciliter l’interprétation des résultats, la visualisation des données est effectuée avec
gnuplotsur un portable (sous OS X)
Création du cluster EC2
Il faut disposer d’un compte AWS (Amazon Web Services). Pour information, Amazon propose de tester (quasi) gratuitement ses services pendant 12 mois à hauteur de 750 heures de consommation mensuelle.
Une fois votre compte créé, installer awscli, le client en ligne de commande de l’API AWS ainsi que l’utilitaire jq, un véritable couteau suisse de JSON. Ce dernier nous sera très utile car la sortie standard du client awscli est au format JSON :
pip install awscli
brew install jqConfigurer votre client awscli :
aws configurePlutôt que d’utiliser directement le client aws, je mets à disposition un ensemble de scripts Shell prêts à l’emploi permettant de mettre en place le cluster EC2 depuis une invite de commande sur un simple portable :
aws-ec2-create_key_pair.sh: créer une paire de clés asymétriquesaws-ec2-create_security_group.sh: créer un groupe de sécuritéaws-ec2-run_instances.sh: créer un nombre prédéfini d’instances EC2aws-ec2-config_ssh.sh: mettre à jour la config SSH locale pour accéder aux instances EC2aws-ec2-get_public_ips.sh: afficher la liste des IP publiques de toutes les instances EC2
Pour récupérer les scripts localement, utiliser les commandes :
git clone https://github.com/ksahnine/datascience-brevet-mentions.git
cd datascience-brevet-mentions/ec2Effectuons pas à pas toutes les opérations de construction du cluster depuis un ordinateur de contrôle (le laptop du schéma ci-dessus) :
- créer une paire de clé asymétriques dont le nom est passé en paramètre (
inovia-kpdans notre cas) :./aws-ec2-create_key_pair.sh inovia-kp
Le script sauvegarde la clé privée dans le fichier~/.ssh/inovia-kp.pem. - créer un groupe de sécurité dont le nom est passé en paramètre (
inovia-sgdans notre cas) :./aws-ec2-create_security_group.sh inovia-sg
Le script rajoute une règle d’accès par SSH mais restreint à l’adresse IP publique de votre ordinateur si vous êtes derrière un routeur. - créer et démarrer 10 instances EC2 de type
t2.micro:./aws-ec2-run_instances.sh inovia-kp inovia-sg 10
Les noms de clé asymétrique et de groupe de sécurité créés ci-dessus sont passés en paramètre. - configurer le fichier
~/.ssh/configpour chacune des instances EC2 :./aws-ec2-config_ssh.sh inovia-kp
Ce script configure automatiquement le fichier~/.ssh/configpour toutes les instances EC2 du cluster, et dont voici un extrait :
Host 52.11.189.180
IdentityFile ~/.ssh/inovia-kp.pem
User ubuntu
StrictHostKeyChecking no
- pour afficher toutes les adresses IP publiques des instances EC2, exécuter le script
./aws-ec2-get_public_ips.sh
A ce stade, vous pouvez accéder à n’importe quelle instance EC2 par SSH sans avoir besoin de saisir un mot de passe. Ex : ssh ubuntu@52.11.189.180
Le script d’extraction des données
Développé en Python, il utilise la technique du harvesting via la librairie BeautifulSoup installable comme suit :
- sous Mac OS X :
sudo pip install beautifulsoup4 - sous Ubuntu :
sudo apt-get install python-bs4(ou viapip)
Je ne vais pas rentrer dans les détails du développement. Je vous renvoie au code source pour plus de détails.
Retenez qu’il fonctionne de la manière suivante :
- la commande
./extract_brevet.pyretourne une liste de triplets (académie, département, commune) dont voici un très court échantillon :
bordeaux Pyrenees-Atlantiques bedous bordeaux Pyrenees-Atlantiques biarritz bordeaux Pyrenees-Atlantiques bidache
- la commande
./extract_brevet.py -a bordeaux -d Pyrenees-Atlantiques -c biarritzextrait les résultats obtenus par les candidats de la commune de Biarritz (dans l’académie de Bordeaux).
Le script produit 2 fichiers (un par série) :- pour la série générale :
output/bordeaux/Pyrenees-Atlantiques/biarritz/Serie-Generale.csv - pour la série professionnelle :
output/bordeaux/Pyrenees-Atlantiques/biarritz/Serie-Professionnelle.csv
Les données extraites sont au format CSV, dont voici un exemple fictif :
- pour la série générale :
bordeaux;Pyrenees-Atlantiques;biarritz;ADMIS;MENTION BIEN;Dupont;Lucie
Distribution des traitements avec GNU Parallel
GNU Parallel est un formidable outil en ligne de commande permettant de paralléliser l’exécution de scripts shell sur un système UNIX.
La parallélisation peut être verticale, c’est-à-dire exploitant tous les coeurs du processeur, et/ou horizontale en distribuant les traitements sur plusieurs machines, ce qui sera le cas dans cet article.
Note : Il n’est pas nécessaire d’installer GNU Parallel sur les machines distantes. Seul un accès SSH suffit.
Installation de GNU Parallel
Installons GNU Parallel sur le portable de contrôle :
- sous Mac OS X :
brew install parallel - sous Ubuntu :
sudo apt-get install parallel
Installation de BeautifulSoup sur les instances EC2
Les instances EC2 sous Ubuntu disposent de l’interpréteur Python mais pas de la librairie BeautifulSoup.
Créons le fichier machines contenant toutes les adresses IP publiques des instances EC2 :
./aws-ec2-get_public_ips.sh > machinesA l’aide de GNU Parallel, installons BeautifulSoup à distance sur l’ensemble des instances EC2 :
parallel --nonall --slf machines "sudo apt-get install python-bs4"Source : parallel-install-bs4.sh
Distribution du traitement d’extraction des données
Dans un premier temps, générons le fichier communes.csv contenant les triplets (académie, dépa rtement, commune) pour l’ensemble des académies :
./extract_brevet.py > communes.csvDans un second temps, lançons les traitements d’extraction répartis sur les instances du cluster par lots de 10 jobs. Ainsi, en rythme de croisière, 100 communes sont traitées simultanément :
parallel -a communes.csv --colsep ' ' -j 10 --basefile ac_scrap.py \
--slf machines "./ac_scrap.py -a {1} -d {2} -c {3} 2> {3}.log"Source : parallel-extract-data.sh
On notera que :
- le flag
-aest suivi du fichier contenant les triplets - le flag
--basefileest suivi du nom du script téléversé et exécuté sur chacune des machines distantes - le flag
--colsepest suivi du séparateur de champ dans le fichier en entrée (le caractère espace dans notre cas). - le flag
-jest suivi du nombre de jobs par machine - le flag
--slfest suivi du fichier contenant la liste des adresses IP des machines du cluster
Distribution du traitement statistique
L’extraction étant terminée, mettons au point deux scripts, l’un affichant tous les prénoms des candidats de série générale, l’autre les candidats ayant obtenu une mention très bien :
$ cat get_prenoms_full.sh
find output -type f -name "Serie-Generale.csv" -exec cat {} \; | cut -d';' -f7
$ cat get_prenoms_meTB.sh
find output -type f -name "Serie-Generale.csv" -exec cat {} \; | grep "TRES BIEN" | cut -d';' -f7Source : get_prenoms_full.sh Source : get_prenoms_meTB.sh
Distribuons les traitements sur le cluster (map) et comptabilisons les prénoms (reduce), triés par ordre alphabétique :
- de tous les candidats :
<pre> parallel –nonall –basefile get_prenoms_full.sh –slf machines \ –pipe “./get_prenoms_full.sh” | sort | uniq -c | \ sort -k2 > stats_brevet_full.csv
</pre>
Source : parallel-get_prenoms_full.sh
- des candidats ayant obtenu une mention TB :
parallel --nonall --basefile get\_prenoms\_meTB.sh --slf machines \\
--pipe "./get\_prenoms\_meTB.sh" | sort | uniq -c | \\
sort -k2 > stats\_brevet\_meTB.csvSource : parallel-get_prenoms_meTB.sh
Le format des fichiers générés est du type :
[...]
1 Hormoz
69 Hortense
2 Hosanna
1 Hosni
[...]Consolidation et visualisation des résultats
Utilisons la commande join pour assembler les fichiers stats_brevet_full.csv et stats_brevet_meTB.csv de façon à obtenir, pour chaque prénom, le nombre total d’occurrences et le nombre de mentions TB :
join -1 2 -2 2 stats_brevet_full.csv stats_brevet_meTB.csv > brevet-mentions-2015.csvLe fichier produit ressemble à ceci :
[…]
Hortense 24 69
Houda 1 11
Houdaifa 1 2
Housni 1 2
[…]Ainsi, sur 69 candidats prénommés Hortense, 24 ont eu une mention TB.
Nous y sommes presque. Rajoutons pour chaque enregistrement ayant plus de 190 candidats, le pourcentage ayant obtenu une mention TB :
join -1 2 -2 2 stats_brevet_meTB.csv stats_brevet_full.csv | \
awk '$3 > 190 { printf("%s %d %d %2.1f\n", $1, $2, $3, ($2/$3)*100) }' > brevet-mentions-2015.csvSource : reduce-join_results.sh
Voici un extrait du fichier brevet-mentions-2015.csv où l’on relève que 16,3 % des prénommées Amandine ont obtenu une mention TB :
[…]
Allan 12 228 5,3
Amandine 144 884 16,3
Ambre 79 403 19,6
[…]Enfin, visualisons le résultat final avec GNU Plot sous la forme d’un nuage de prénoms où le nombre de candidats est représenté en ordonnée et le pourcentage de mention TB en abscisse :
gnuplot <<EOF
plot "brevet-mentions-2015.csv" u 4:3:1 w labels rotate by 20 font "Helvetica,8"
EOF